Every SEO professional stresses the importance of having your pages indexed by Google. However, the issue is often more complex than a straightforward directive, especially when Google is not indexing certain pages.
A variety of factors can prevent pages from being indexed. While these issues may not always be alarming, they do warrant attention. Common problems include poor content quality, duplicate content, and technical glitches that block pages from indexing. Conversely, some pages might be intentionally excluded from indexing, in which case no action is needed.
The first step in tackling indexing issues—particularly those related to Google, not indexing pages—is to consult your Google Search Console report. This tool offers valuable insights into why specific pages aren’t appearing in search results, along with guidance on how to rectify these issues, if necessary.
Let’s delve deeper into the complexities surrounding Google not indexing pages, particularly when Google is the search engine in question. We’ll look at common Search Console alerts and discuss steps you can take to ensure proper indexing. Keep in mind that some alerts may not require any action on your part.
Indexing Web Pages by Search Engines
When it comes to achieving high search engine rankings, the first step is ensuring your website’s pages are indexed by Google. Most SEO services providers focus on optimizing your site for this crucial process.
First, let’s quickly review the basics. Before your pages can show up in search results, they must be indexed by Google. The search engine uses a technology known as Googlebot to crawl your web pages automatically and gather information.
Googlebot analyzes the text on each page and follows any links it finds, continuing this process for each subsequent link and submitted page. In this way, Google creates a comprehensive index of web pages from across the internet.
When it comes to indexing a page, Google’s algorithms consider various criteria. These include content quality, page popularity, schema markup, and the value of internal and external links. These factors help Google assess each page’s relevance and quality.
When a user conducts a search, Google’s algorithm consults this index to generate results. The most relevant pages are displayed first in search engine results pages (SERPs), followed by less relevant options.
Why Certain Pages Should Remain Unindexed
It’s natural to feel a bit overwhelmed when confronted with a multitude of Search Console warnings. However, it’s crucial to understand that not every page on your website needs to be indexed. In some instances, ignoring these warnings is the right course of action.
For example, consider duplicate or alternate pages. It’s often appropriate for these to go unindexed. If you find a page that is not indexed and is flagged as a duplicate, it usually means that Google has already identified and indexed the correct canonical page.
You can confirm this by using the URL Inspection tool . If the correct canonical page has indeed been indexed, there’s no need for concern or further action regarding these warnings.
Another case where pages may intentionally remain unindexed involves areas of your website that aren’t meant for public viewing, such as a shopping cart or an account page with sensitive information. Such pages are often purposely excluded from indexing with a “noindex” tag to optimize the crawl budget, particularly for larger websites.
In instances where a page has been deliberately left unindexed for valid reasons, this warning will naturally persist in your Index Coverage Report. No further action is required.
Common Reasons for Indexing Problems
Problems with indexing can arise for a variety of reasons. These often include issues like duplicate content that lacks a proper canonical tag, difficulties in page accessibility, conflicts with the robots.txt file, improperly executed redirects, and complications with JavaScript rendering.
Sometimes, Google may not even be aware that a page exists. This could happen if the page is new, omitted from the sitemap, or if there is no link leading Googlebot to it. Note that even after you’ve submitted a crawl request, it may take several weeks for the new page to get indexed.
Additionally, Google may opt not to index content that is poorly optimized or lacks substantial information, commonly referred to as “thin content.” To steer clear of such indexing issues, make sure your pages are content-rich, well-optimized, easily accessible, and loaded correctly.
For a more in-depth understanding of these challenges, it’s crucial to familiarize yourself with the Search Console Dashboard and how to interpret your Index Coverage Report. Mastering these basics will equip you to tackle potential indexing issues effectively.
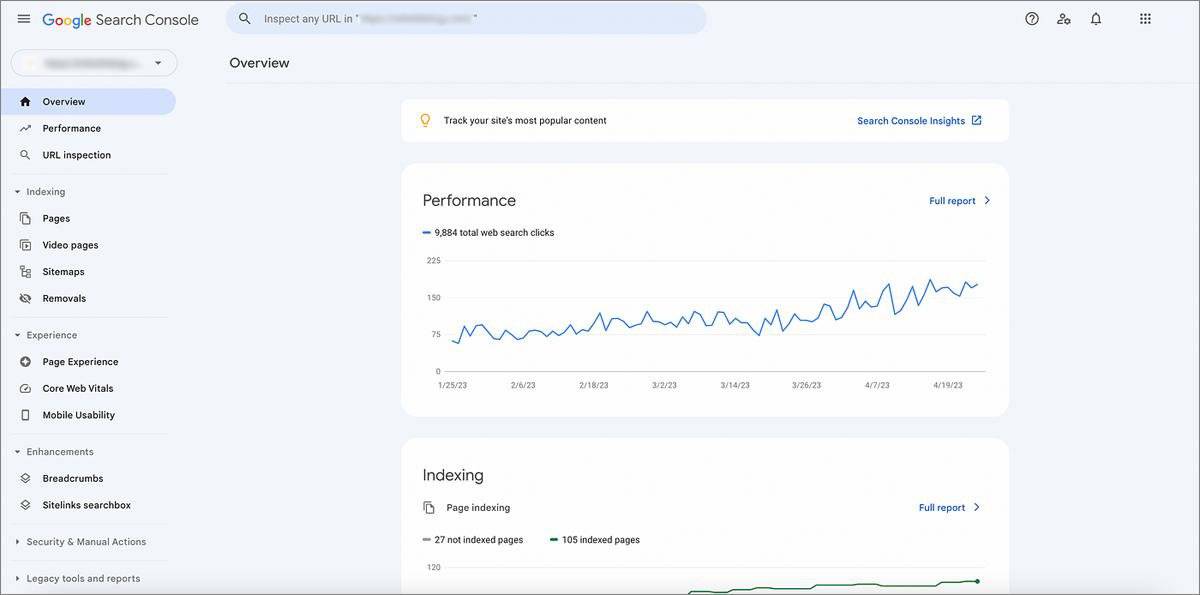
Navigating your Google Search Console Dashboard might initially seem daunting, but here’s a straightforward breakdown of each section to help you make the most of it.
- Overview Report : This report provides a holistic view of your website’s performance, featuring data on clicks, impressions, click-through rates, and average positioning. Use this information to assess how frequently your site appears in search results, identify your most visited pages, and determine the search queries driving the most clicks.
- Queries Report : This section offers insights into the specific search queries that lead users to your site, along with their respective rankings. It’s an invaluable resource for understanding which keywords generate the most impressions, clicks, and click-through rates. This data is crucial for deciding which keywords should take precedence in your SEO strategies.
- Pages Report : This report focuses on the performance of individual webpages, delivering comprehensive metrics on clicks, impressions, click-through rates, and keyword rankings. Utilize this report to spotlight top-performing pages that outclass your competition and direct your optimization efforts accordingly. Consider it your strategic roadmap for maximizing results .
- Links Report : Finally, we have the Links Report, which reveals information about both external and internal links pointing to your webpages. Think of this as your investigative tool for spotting broken links, which could hurt your SEO and user experience. Regularly consult this report to maintain a healthy link profile and ensure everything is functioning as it should .
In summary, you’re now better equipped to navigate the Google Search Console Dashboard. By diving into these reports and analyzing the data, you’ll be well-prepared to make informed decisions that can significantly improve your website’s performance.
Also Read: 20 BEST SMALL SEO TOOLS TO IMPROVE YOUR RANKINGS
Understanding the Google Search Console Page Indexing Report
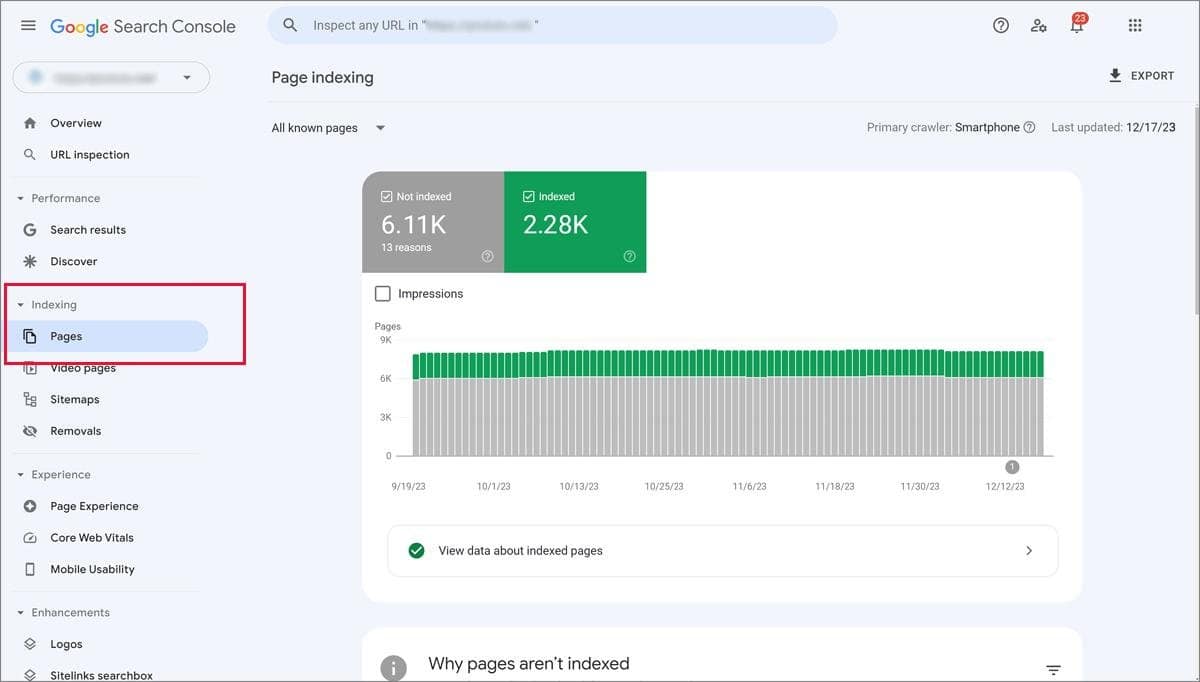
The Page Indexing Report in Google Search Console is your go-to resource for quickly identifying which pages on your website are indexed by Google and which aren’t. To access it, click on “Indexing” in the sidebar and then choose the “Pages” option.
Upon arriving, you’ll see a summary page featuring a graph and a current count of indexed and non-indexed pages. Monitor the trend line that correlates with the frequency of your content publishing. Any abrupt changes could indicate a potential issue that needs further investigation.
Your end goal should be to index the canonical version of each major group of pages. Keep an eye on the different states of the pages you’ve submitted for indexing:
- Crawl Status : In this stage, Googlebot is actively crawling and evaluating the page to decide whether its content is sufficiently valuable and relevant to be included in Google’s search index. In layman’s terms, Googlebot is determining if the page merits inclusion in search results.
- Indexing Status : At this point, Googlebot has crawled the page, evaluated its content, and deemed it worthy of indexing. While this status signifies that the page could appear in search results, it doesn’t assure immediate visibility or high ranking .
- Serving Status : When a page reaches this status, it means it has been indexed and is now actively appearing in Google’s search results. Users can find and click on this page when they search for relevant keywords, confirming that it is live on Google’s search engine.
In your Index Coverage Report, you’ll find four tabs: Error, Valid with Warnings, Valid, and Excluded. To diagnose and address indexing issues, focus on the Error tab.
Scroll down to the Details section, where errors are categorized for easier analysis:
- Why Pages Aren’t Indexed Table : This table lists status codes explaining why Google hasn’t indexed certain URLs. By clicking on individual rows, you can delve deeper into which URLs are affected and view a history of your site’s indexing issues.
- Improve Page Experience Table : This section features pages that Google has already indexed but recommends enhancing for a better user experience and search visibility.
- View Indexed Page Data : This option directs you to a list of all the pages currently indexed by Google. It also provides historical data to help you track your site’s indexing trends over time.
Your primary focus should be on the “Why Pages Aren’t Indexed Table” to pinpoint and resolve any indexing issues flagged by the Search Console.
Also Read: IMPORTANT FACTS ABOUT NO FOLLOW LINKS!
Utilizing the URL Inspection Tool for Detecting Google not Indexing Pages Issues

Let’s explore how to use the URL Inspection Tool in Google Search Console to comprehensively understand how Google views various pages on your website. This tool is invaluable for obtaining detailed insights into a specific page’s indexing status and any roadblocks that might impede its visibility in search results.
Here’s a step-by-step guide to effectively utilizing the URL Inspection Tool:
- Access the Main GSC Header
-
- Begin by navigating the Google Search Console’s main header and locating the URL Inspection Tool.
- Enter the Webpage URL
-
- After you’ve located the tool, enter the URL of the webpage you wish to investigate and hit Enter.
- Interpret the Results
-
- The tool will reveal whether the page is indexed, pending indexing, or not indexed at all.
- Dealing With Unindexed Pages
-
- If the page isn’t indexed, the tool will offer reasons for this status. The information provided can be crucial for understanding common indexing issues and planning your next steps.
Common Search Console Issues and Their Solutions
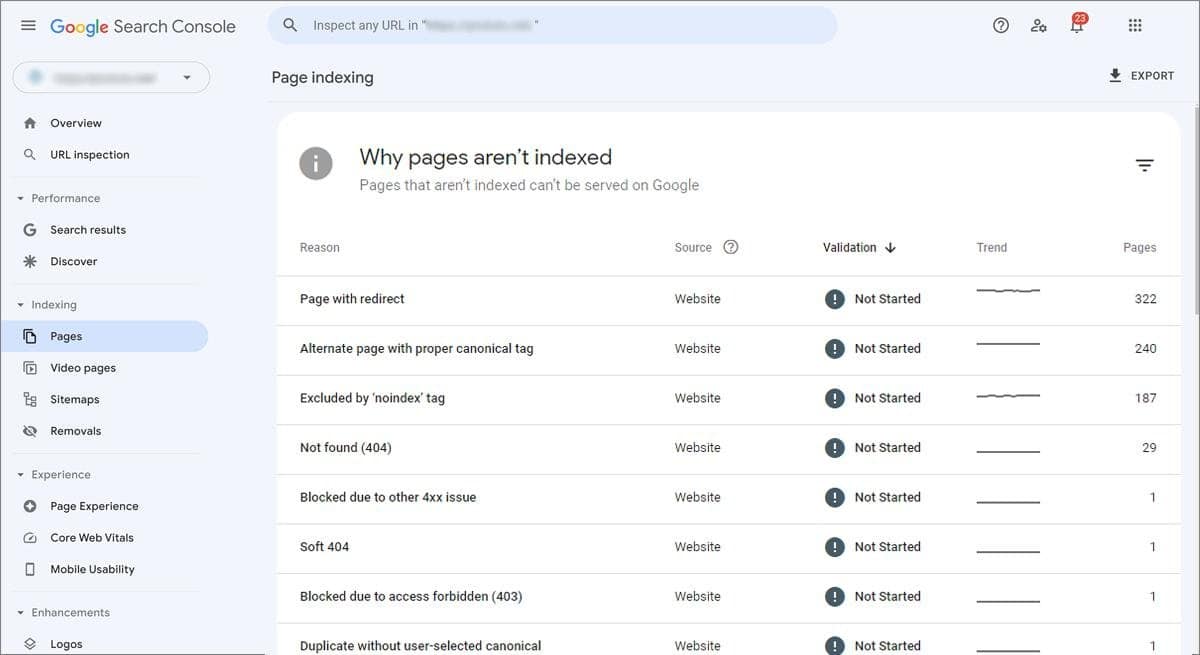
Let’s examine some common Search Console errors, how to resolve them, and when a warning might not warrant immediate action.
-
Server Error (5xx)
When you come across a server error (5xx), it suggests that Googlebot faced issues while attempting to crawl and index your content. If you can access the website through your browser, the server issue is likely temporary and already resolved. If the problem persists, consider consulting with your developer or hosting provider for a solution.
-
No Domain Name
If your website is live but doesn’t have a domain name, it will be accessible only via its IP address. This poses a problem because Google will struggle to identify and index your site, leading to an IP address instead of a domain name appearing in the address bar.
To address this, make sure your URL is correctly set up in your WordPress settings or any other hosting platform you’re using. Additionally, consider implementing 301 redirects to channel traffic from the IP address version to your actual domain, ensuring that users reach the correct version of your website.
-
Redirect Error
The warning message you’re encountering indicates that Googlebot faced challenges while trying to crawl and index your webpage due to a redirect issue. Such issues commonly arise when the redirection becomes overly complicated. This can manifest as long chains of redirects, cyclical redirects that lead back to the original page, or unusually long redirect URLs. Redirect problems may also occur if a URL in the redirect chain is flawed or empty.
To rectify this, scrutinize your redirect setup to identify the specific issue. Focus on simplifying the redirect chain. If possible, minimize the number of redirects and ensure that all pages in the chain load properly. Doing so should make it easier for Googlebot to navigate your site.
-
URL Marked “Noindex”
If your page has a “noindex” tag, it means Google won’t include this page in search results. If visibility is a concern, consider whether you actually want users to find this page via search. If you decide that it’s not necessary, no further action is needed.
-
Website Is Too New
If your website is newly launched, Google may not have indexed it yet. This is quite common and not a cause for concern. Google needs varying amounts of time, anywhere from a few hours to several weeks, to index new content.
In the interim, continue to update your site regularly with fresh and relevant content. This not only keeps your site engaging but also establishes your brand as a trusted source of information. Once Google indexes your site, a solid foundation of quality content will likely improve your search rankings and build trust with your audience.
-
Submitted URL Encounters a Crawling Issue
When you see this warning, it means that your page was in the process of being indexed when Googlebot encountered an obstacle.
Don’t worry. Utilize the URL Inspection Tool to pinpoint the problem. Sometimes, Google faces issues loading a site due to complexities with elements like JavaScript, CSS, or certain images. Inspect the page personally; if it seems fine, you can resubmit it for indexing. If you do find any issues, however, fix them first before attempting re-indexing. It’s as straightforward as that!
-
Crawled But Not Indexed
Your page was crawled by Google but wasn’t indexed, and there’s no clear reason why. Consider enhancing the quality and optimization of your content to improve your chances of being indexed in the next crawl. There’s generally no need to resubmit a crawl request in this case.
-
Blocked By Page Removal Tool
This particular page wasn’t indexed because it was subjected to a removal request via a page removal tool. It’s crucial to check whether this action was intentional. Remember, removal requests are only valid for 90 days. After this period, the page is likely to be re-indexed unless you employ the appropriate “noindex” tag, set up a redirect, or delete the page entirely.
-
Discovered
Google discovered the page but didn’t index it. For some unspecified reason, Google had to reschedule the crawl. There’s no immediate cause for concern, as Google intends to reattempt the crawl later.
If you find that this issue recurs frequently, particularly if your website has more than 10,000 pages, it may indicate server overload when Google tries to crawl the site. In such instances, consult your hosting provider to determine the issue and necessary actions.
Another possible explanation is exceeding your site’s crawl budget. This might occur if your content management system auto-generates a large volume of content, if there’s a significant amount of user-generated content, or if you have multiple filtered product category pages. To mitigate this, you might want to remove redundant content or prevent superfluous pages from being indexed.
-
Blocked By Robots.txt
The page is currently being blocked from being crawled because of directives in your site’s robots.txt file. While Google may continue to index other parts of your website, it’s essential to verify that this specific blockage is intentional. If you wish to keep the page from being indexed in the future, make sure to apply the appropriate “noindex” directive.
-
Missing Sitemap
A sitemap acts as an organized inventory of all elements on your website, including pages, videos, files, and interconnecting links. It serves as a blueprint that helps Google efficiently navigate and index your site. Without a sitemap, Google may have trouble comprehensively crawling your website.
When creating your sitemap, it’s generally better to use XML over HTML. XML is designed to improve search engine efficiency. After creating the sitemap, you can either submit it directly via Google Search Console or include it in your robots.txt file, which guides Google on which URLs to crawl and index.
-
Blocked Due to Unauthorized Request (401)
This issue typically arises when a page requires some form of authorization, like a password. Ensure that the authorization settings are configured correctly to resolve the issue.
Another scenario to consider is when a developer links to pages on a staging site while it’s under construction and forgets to update those links when the site goes live. Updating the links should fix this problem.
-
Blocked Due to Access Forbidden (403)
This is akin to a 401 error; the page isn’t indexed because Googlebot lacks the necessary access credentials. To get the page indexed, either allow access to users who aren’t logged in or specifically permit Googlebot to access the page without authentication.
-
Poor Site Structure
Google prioritizes websites that offer a good user experience when indexing. If your site is difficult to navigate, it might be less visible to search engines. Moreover, a poorly structured site can hinder Google’s ability to crawl your pages effectively. To address this, make sure your website has a logical structure and employs intuitive linking, facilitating easier navigation for both users and Google.
-
Crawl Anomaly
An issue is preventing the page from being crawled and indexed. One common reason could be that the website no longer exists or that it redirects to a 404 error page. Make sure any redirect chains involving this page are simple and direct and that the final destination page loads correctly.
-
Alternate Page With the Appropriate Canonical Tag
In this situation, the page has duplicate content but is already linked to the correct canonical page. There’s no need for further action unless you’re considering consolidating the pages under a single URL.
-
Duplicate Without User-Selected Canonical
This warning means that duplicate pages exist, but none has been marked as the canonical (primary) version. Google has autonomously identified one as the canonical page. If you think Google has chosen the wrong URL, specify your preferred canonical page using the appropriate canonical tag.
-
Duplicate Page in Non-HTML Format
Google has found a duplicate page on your site that is not in HTML format, such as a PDF. The original page is marked as the canonical version, signaling that it’s the preferred one. This is merely a notification, and no action is necessary on your part, although it’s worth noting that these duplicate pages should not be indexed.
-
Duplicate Page With Google-Selected Canonical
Here, Google has selected a canonical URL that differs from the user-specified one. Google believes another version of the page would serve as a better canonical candidate. This situation can occur if you originally set one version as canonical but later redirected to another. It’s recommended to review the canonical tags for this set of pages to ensure the correct version is designated.
-
Page Not Found (404)
A “Page Not Found (404)” error signifies that Google tried to access a URL that was not requested for crawling and found it unavailable, with no redirect set up. If possible, establish a 301 redirect to a relevant page. While it’s preferable to avoid 404 errors, if no suitable redirect target exists, leaving the 404 error in place may be the best course of action.
-
Page With Redirect
In this situation, a redirected page was not indexed because it was intentionally pointed elsewhere. If the redirect was purposeful, no further action is needed.
-
Queued for Crawling
Your page is in the queue for crawling. Simply check back later for any updates.
-
Soft 404
This page wasn’t indexed because it lacks substantial value. A common issue is a user-friendly “not found” message without the appropriate 404 HTTP response code. You have a few options: implement a 301 redirect to a relevant page, update the content with useful information, or ensure it returns a proper 404 code.
-
Submitted URL Dropped
Your submitted URL was removed from the index without a specific reason. Time for a refresh! Add new and valuable content, refine your optimization strategy, and you’ll improve your chances of being re-indexed. Alternatively, a 301 redirect can guide users to the appropriate page.
-
Recent Web Redesign
If you’ve recently overhauled your website—whether it’s a redesign, rebranding, or other significant changes—it’s possible that Google has not yet indexed the new layout. To make sure your changes are accurately reflected in search results, submit a recrawl request via Google Search Console. This action will prompt Google to revisit and re-evaluate your site, incorporating the new changes into its index.
This step is particularly beneficial if you’ve enhanced your site’s crawlability. Firstly, ensure your website complies with standard guidelines. Then, review the URL and choose the “request indexing” option.
By doing so, you’re essentially inviting Google to crawl and index your website’s pages, making them eligible for display in search engine results pages (SERPs). It’s a simple but effective way to make sure Google doesn’t miss any of your recent updates.
-
Orphan Pages
Google can’t crawl orphan pages if they’re disconnected from the rest of your website. To fix this, identify these pages and link them internally to other parts of your site. If an orphan page contains thin or duplicate content that doesn’t add value, consider removing it.
Google may view it as a gateway page. Should you decide to delete it, make sure to set up a 301 redirect to a relevant URL, especially if the page is linked from elsewhere on your site.
-
Not Mobile-Friendly
With more than half of all web searches conducted on mobile devices, Google prioritizes mobile-friendly websites. If your site isn’t optimized for mobile, it’s less likely to be indexed by Google. To improve mobile usability, think about adopting responsive design, optimizing image sizes, and improving load times. Also, removing pop-ups and designing for easy finger navigation can enhance the user experience.
-
Not ADA Compliant
Google assesses web pages for accessibility. If your site doesn’t meet ADA compliance guidelines, it may not be indexed. Common issues include missing alt text, difficult-to-read fonts, and inadequate keyboard-only navigation.
Online tools are available to check your website for ADA compliance. Consider making design changes to meet these standards, as it could speed up the Google indexing process.
-
Exceeded Crawl Budget
Every website has a crawl budget, which limits the number of pages Googlebot will visit. Check your Crawl Stats Report in Google Search Console to find out your specific limit. Once reached, Google will stop indexing new pages. This is especially relevant for larger websites. After a site audit, you can either consolidate existing pages or use code to direct Google away from certain pages.
-
Received a Google Penalty
If you’re struggling to understand why your site isn’t being indexed, consider the possibility of Google penalties. These could be due to unnatural links, harmful content, or misleading redirects. To check for penalties, go to Google Search Console and navigate to the “Security & Manual Actions” section.
Here, you’ll find information on any penalties and guidance on how to resolve them. Adhering to Google’s Webmaster Guidelines is crucial for avoiding future issues.
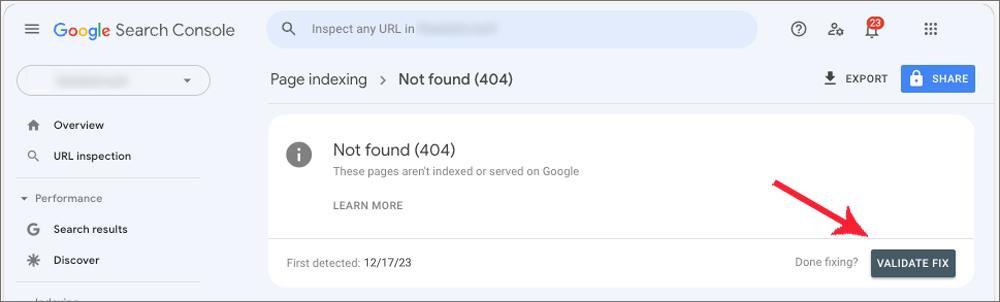
How to Tell Google You’ve Resolved an Indexing Problem
If you’ve updated your website and want Google to recognize these changes, follow these steps to inform Google that your page is ready to be re-crawled and re-indexed:
Step 1: Access the Page Indexing Report
Start by opening the Page Indexing Report in Google Search Console. Here, you’ll find details on the indexing status of your webpages.
Step 2: Choose a URL for Resubmission
While in the Page Indexing Report, identify the specific URL you’ve amended and wish to resubmit for indexing.
Step 3: Review and Address Issues
Examine the information provided in the report meticulously. Make sure you’ve resolved all identified issues. This step is vital to ensure your page is primed for re-crawling.
Step 4: Select “Validate Fix” From the Drop-Down Menu
After confirming that all issues have been addressed, click “Validate Fix.” This will inform Google that you’ve rectified the problems, and your page is now ready for another crawl.
Step 5: Wait for Google to Send You a Confirmation Email
Google will send you an email to confirm the start of the validation process. Keep in mind that this can take several weeks, so your patience is crucial.
Step 6: Indexing and Ranking Opportunities
Once Google has successfully validated the fixes, your page should be indexed and will start appearing in the Search Engine Results Pages (SERPs) for relevant queries.
By adhering to these steps meticulously, you effectively signal to Google that your page is in optimal condition and ready for indexing.
Conclusion
In conclusion, encountering issues with Google’s failure to index your pages can initially be frustrating and perplexing. However, the process of resolving common Search Console warnings is usually straightforward. There are logical reasons why certain pages are excluded from indexing.
Understanding the importance of common Search Console warnings and knowing how to address them is a crucial first step in resolving page indexing issues. With a solid understanding of these elements, ensuring that your relevant pages are indexed becomes a much simpler task, leading to the desired outcomes.
FAQs
How can I check whether my pages have been indexed?
To verify if your pages are indexed, go to Google Search Console and consult the ‘Coverage’ report. This will show you which pages have been indexed and alert you to any potential issues.
What if I’ve resolved errors, but my pages still aren’t indexed?
If you’ve resolved the identified issues, but your pages are still not indexed, head back to Google Search Console and request a re-crawl and re-indexing of your updated pages.
Can server issues impact indexing?
Absolutely. Frequent server downtime can impede search engine bots from accessing and indexing your pages. To ensure uninterrupted indexing, make sure your server remains stable.
What if my website has recently undergone a redesign?
If your website has recently undergone a redesign, it’s essential to thoroughly review your Google Search Console reports for any new indexing issues. Structural or content changes on your website can affect how search engines index your pages.






